DiffVQA: Video Quality Assessment Using Diffusion Feature Extractor
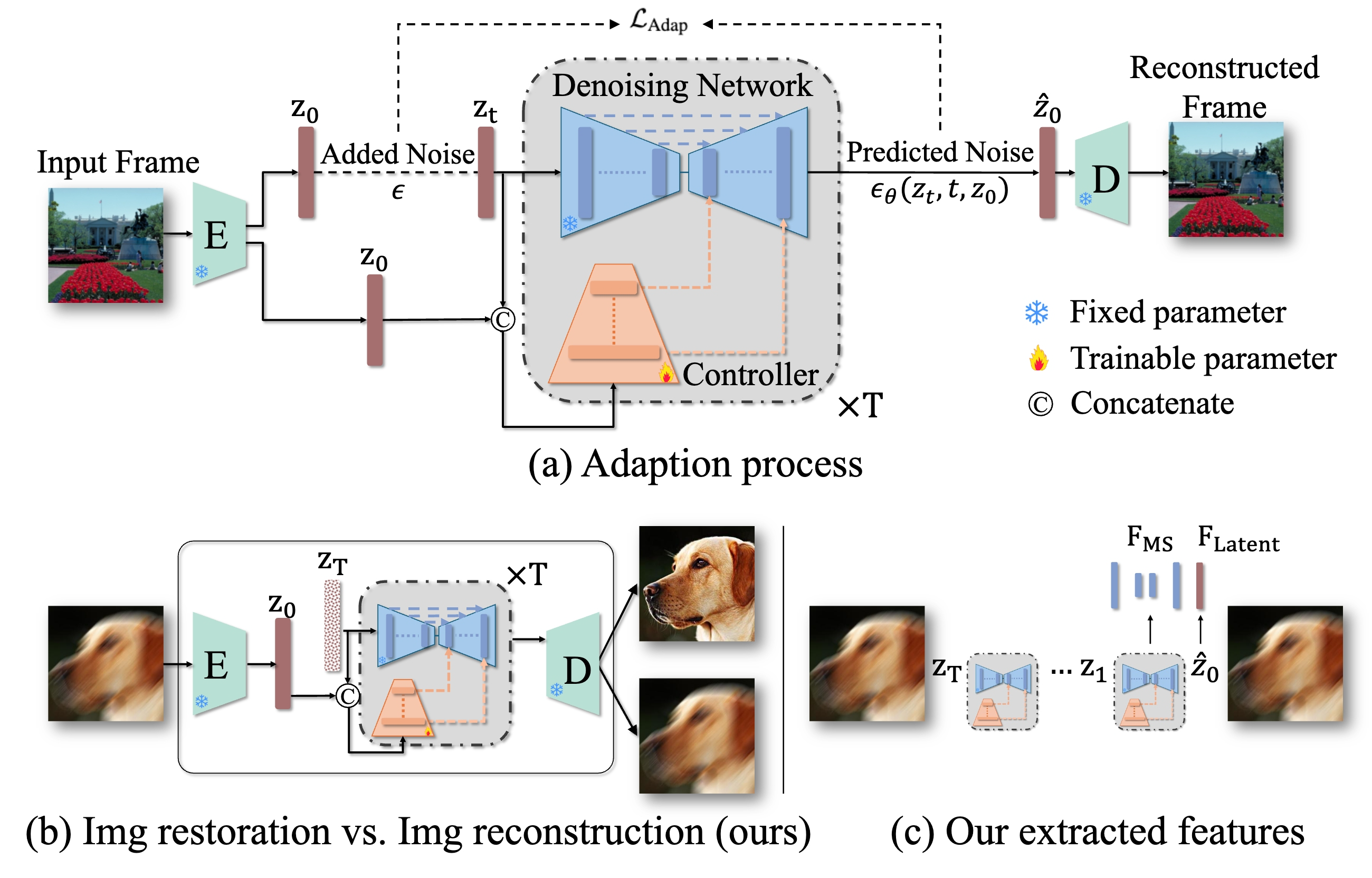
DiffVQA explores a simple but important question: can a diffusion model, originally trained for image generation, become a stronger feature extractor for Video Quality Assessment? Instead of generating new images, DiffVQA adapts Stable Diffusion to reconstruct the same input frame. If the model can faithfully reconstruct frames with noise, blur, low light, and other degradations, then its internal features are likely to preserve the semantic and distortion cues needed for perceptual quality prediction.
The framework combines three key ideas: Diffusion Feature Extractor, Semantic / Distortion Branches, and Temporal Coherence Modeling. The final quality score is predicted by combining diffusion-based frame features with a Mamba-based temporal module.
Abstract
Video Quality Assessment (VQA) estimates how humans perceive video quality. Although recent CNN- and ViT-based no-reference VQA methods have achieved strong performance, they still face difficulties in real-world user-generated videos, where content, distortions, and temporal changes are highly diverse. This limitation is partly caused by the restricted scale and diversity of available VQA datasets.
We propose DiffVQA, a no-reference VQA framework that leverages the generalization ability of diffusion models pre-trained on large-scale visual data. DiffVQA adapts Stable Diffusion to reconstruct identical input frames through an additional Controller. After adaptation, the diffusion model is used as a feature extractor rather than a generator. It extracts semantic features from resized frames and distortion-aware features from randomly cropped frames. A parallel Mamba-based Temporal Coherence Augmentation Block further models long-range video dynamics. Experiments across multiple UGC-VQA datasets demonstrate that DiffVQA achieves strong intra-dataset performance and robust cross-dataset generalization.
Method Overview
DiffVQA is built around an adapted diffusion feature extractor. For each video frame, two visual views are created: a resized view and a randomly cropped view. The resized branch is designed to preserve global semantic information, while the random crop branch focuses on local distortion details. Both branches are processed by the adapted diffusion model, producing latent and multi-scale denoising features.
These diffusion features are refined by three lightweight modules. DFF fuses latent and multi-scale diffusion features, TDM captures temporal differences between adjacent frames, and FFF aggregates refined features across frames. In parallel, TCAB uses a Mamba-based sequence modeling design to capture temporal coherence over the whole video. Finally, the model predicts frame-level quality scores and frame-level weights, then computes the final video quality score by weighted summation.
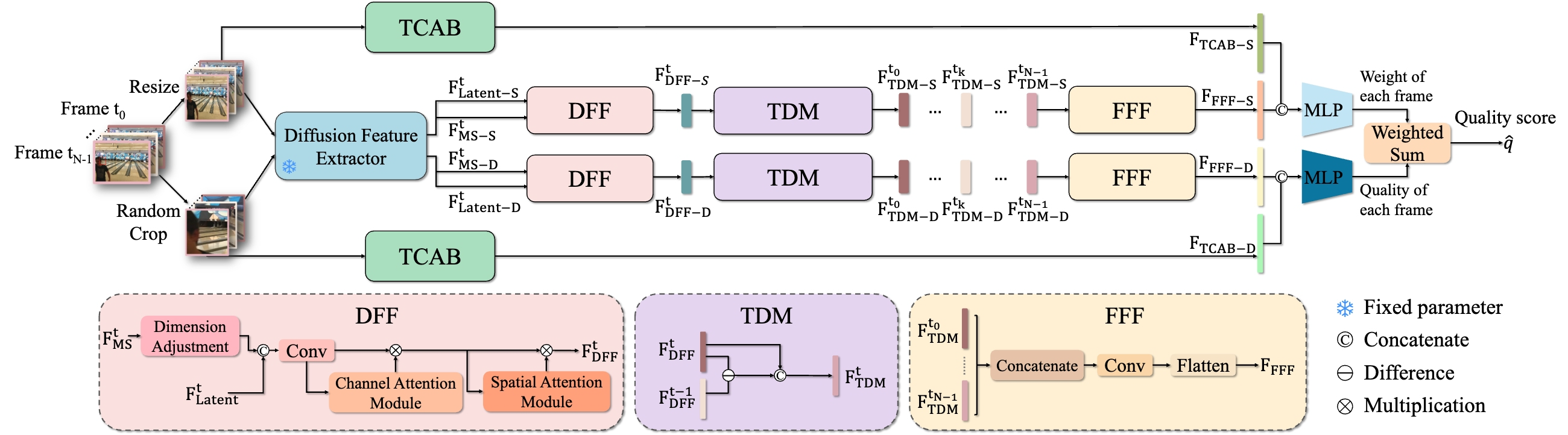
Diffusion Feature Extractor
Pre-trained diffusion models are originally designed for text-to-image generation, so they cannot be directly used as image feature extractors. DiffVQA solves this by adding a trainable Controller to guide Stable Diffusion to reconstruct the identical input frame. During adaptation, the input frame is encoded into latent space, noise is added, and the denoising network learns to predict the added noise under the guidance of the Controller. The text condition is set to null, and only the Controller is optimized.
After adaptation, DiffVQA uses the reconstructed latent feature and the multi-scale denoising features at the final denoising step as video-quality-aware representations. This design allows the diffusion model to preserve both high-level content and low-level degradation patterns, which are both important for VQA.
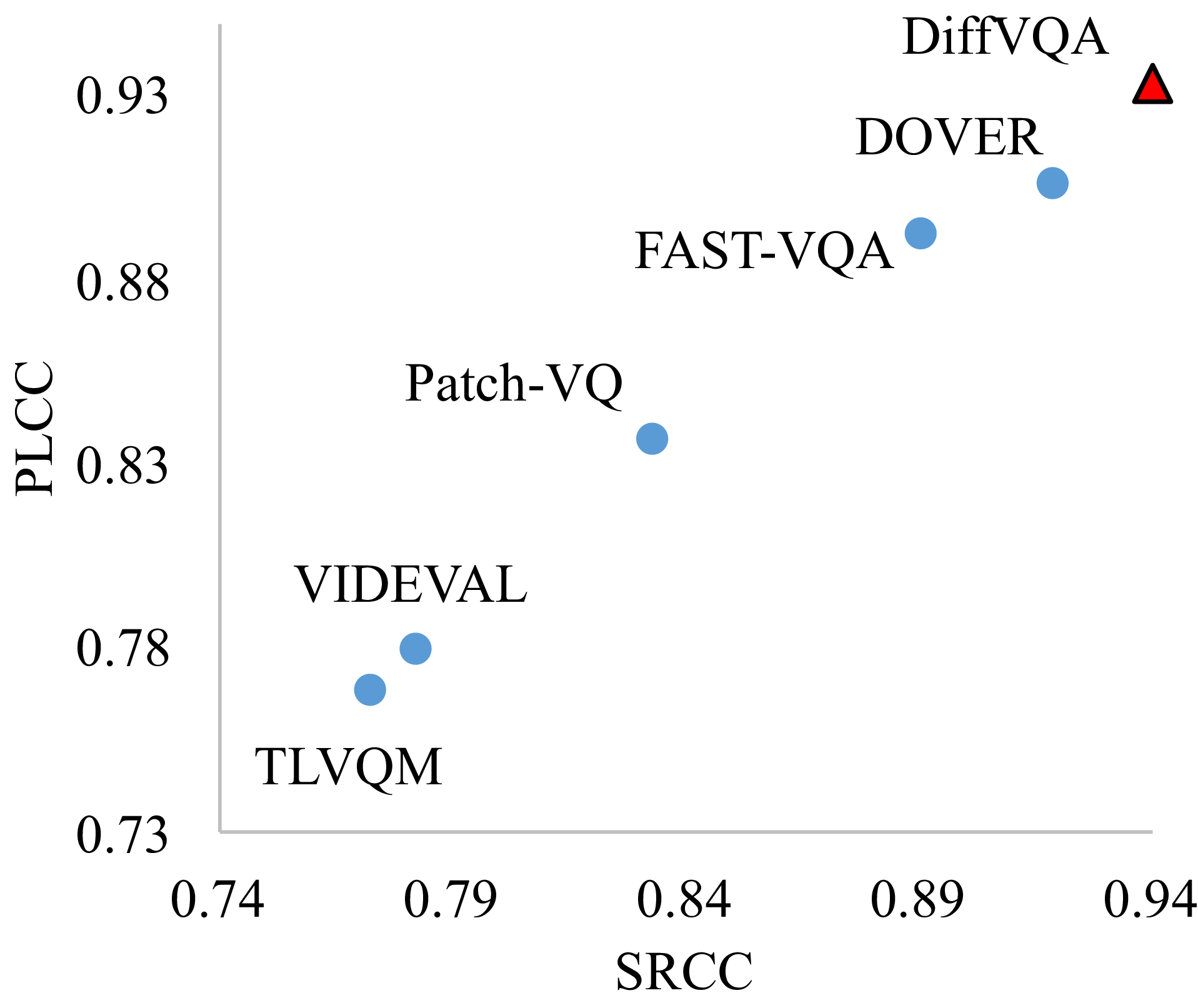
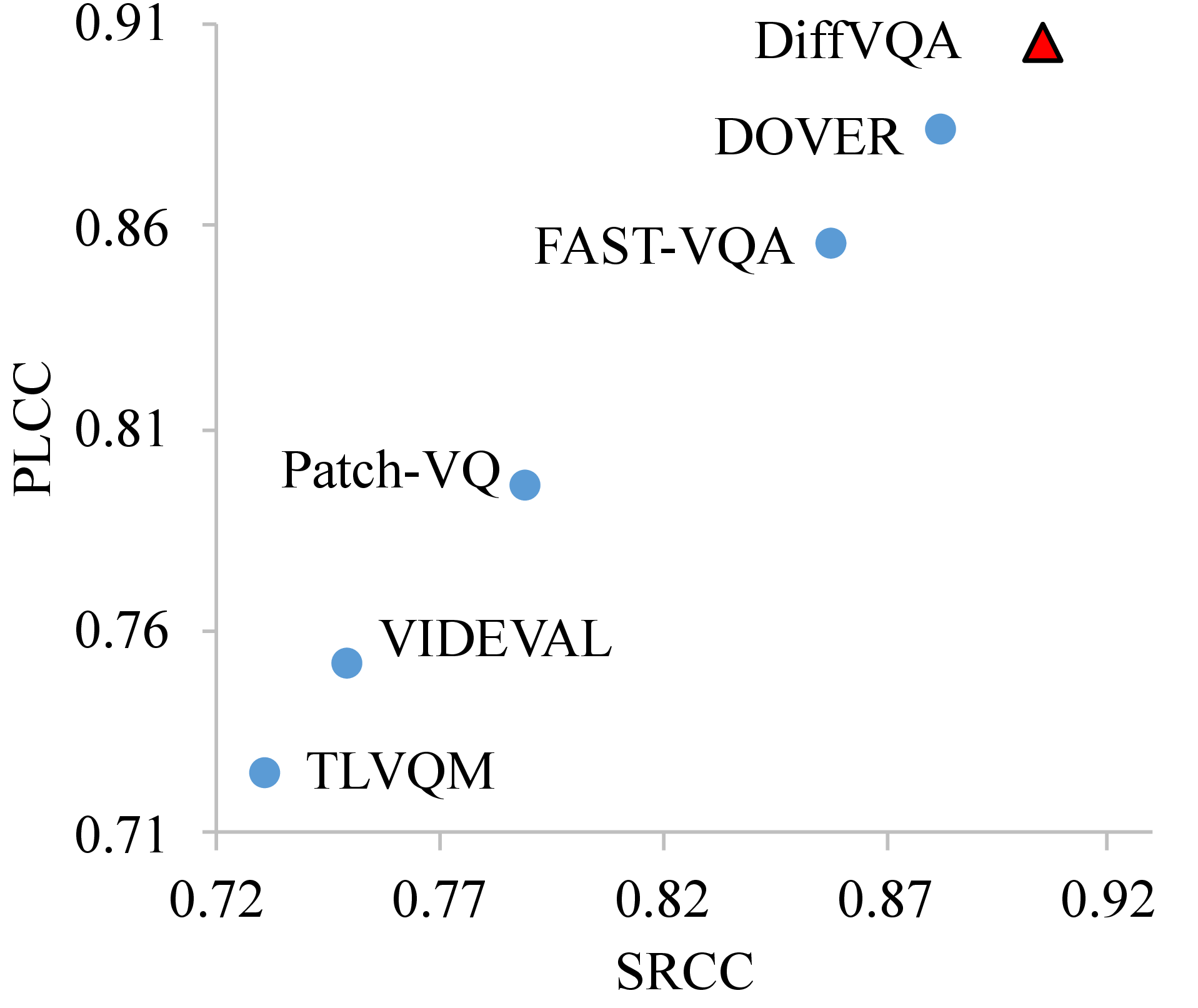
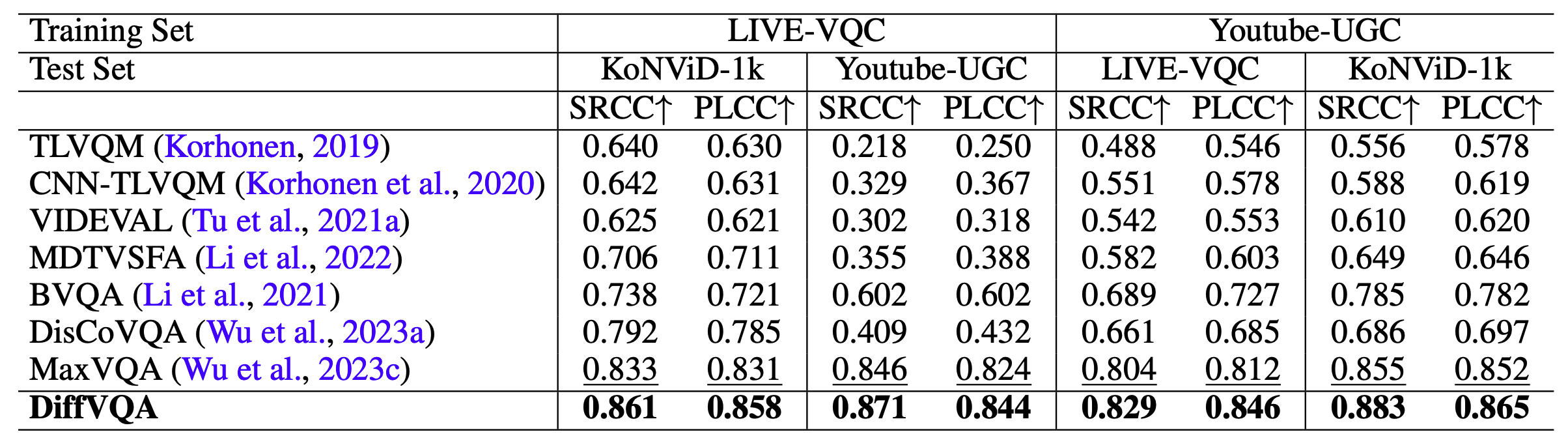
Quantitative Results
We evaluate DiffVQA across multiple UGC-VQA datasets to validate its effectiveness. After pre-training on LSVQ and fine-tuning on LIVE-VQC, KoNViD-1k, and YouTube-UGC, DiffVQA achieves strong performance across all three datasets, demonstrating its ability to accurately predict human perceptual quality in diverse user-generated videos. To further assess generalization, we conduct cross-dataset evaluations by training on one dataset and testing on another. DiffVQA consistently shows robust performance across different training and testing dataset combinations, highlighting its generalization capability across real-world video quality assessment scenarios.
These results demonstrate that leveraging a diffusion model as a feature extractor can provide effective quality-aware representations for VQA, leading to state-of-the-art performance on standard UGC-VQA benchmarks and strong cross-dataset generalization.
Examples of Reconstructed Results
The adapted diffusion model is trained to reconstruct the input frame rather than restore it into a cleaner version. This distinction is important: for video quality assessment, degradations such as noise, blur, and low light are not artifacts to be removed, but perceptual signals that should be preserved and represented.
The examples below compare the input frame, reconstructed frame, and error map. The small reconstruction error indicates that the adapted diffusion model successfully retains both semantic content and distortion information, supporting its use as a feature extractor for VQA.

BibTeX
@misc{chen2025diffvqavideoqualityassessment,
title={DiffVQA: Video Quality Assessment Using Diffusion Feature Extractor},
author={Wei-Ting Chen and Yu-Jiet Vong and Yi-Tsung Lee and Sy-Yen Kuo and Qiang Gao and Sizhuo Ma and Jian Wang},
year={2025},
eprint={2505.03261},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2505.03261},
}